Despite operating with a team 40 times smaller than OpenAI and lacking access to unlimited compute or top-tier NVIDIA chips, DeepSeek has managed to create an open-source marvel. DeepSeek V4 is a massive 1.6 trillion parameter model with an enormous 1 million token context window, essentially allowing it to memorize the equivalent of the entire Harry Potter series in its short-term memory.
Because the team did not have the luxury of solving problems with brute-force computation, they engineered a series of brilliant, interwoven architectural solutions that make the impossible possible.
Hybrid Attention Architecture: Solving the Memory Bottleneck
At a 1-million-token context window, traditional attention mechanisms — where every word is compared to every past word — create an astronomical number of calculations and require massive GPU memory for the Key-Value (KV) cache. DeepSeek's shrewd workaround was to stop treating all past information equally. Instead of doing massive computations over the entire past, they deployed three parallel pathways.
Compressed Sparse Attention (CSA): This groups small chunks of tokens (e.g., 4 at a time) into a single, dense summary, immediately reducing sequence length. A mechanism called the Lightning Indexer acts as a fast internal search engine to rapidly score and select only the most relevant compressed blocks for the current context, skipping the rest entirely.
Heavily Compressed Attention (HCA): For broad, high-level understanding, HCA aggressively compresses large chunks — like 128 tokens or an entire paragraph — into a single mathematical representation. Because the sequence becomes so short, the model can afford to view the entire history at once.
Sliding Window Attention: To compensate for the loss of precise details during compression, this pathway keeps the most recent 128 words entirely uncompressed, tracking immediate context with perfect exact fidelity.
By intertwining these three strategies, DeepSeek V4 achieves unparalleled efficiency, running on roughly 27% of the compute required by its predecessor and slashing KV cache memory footprint by 90%.
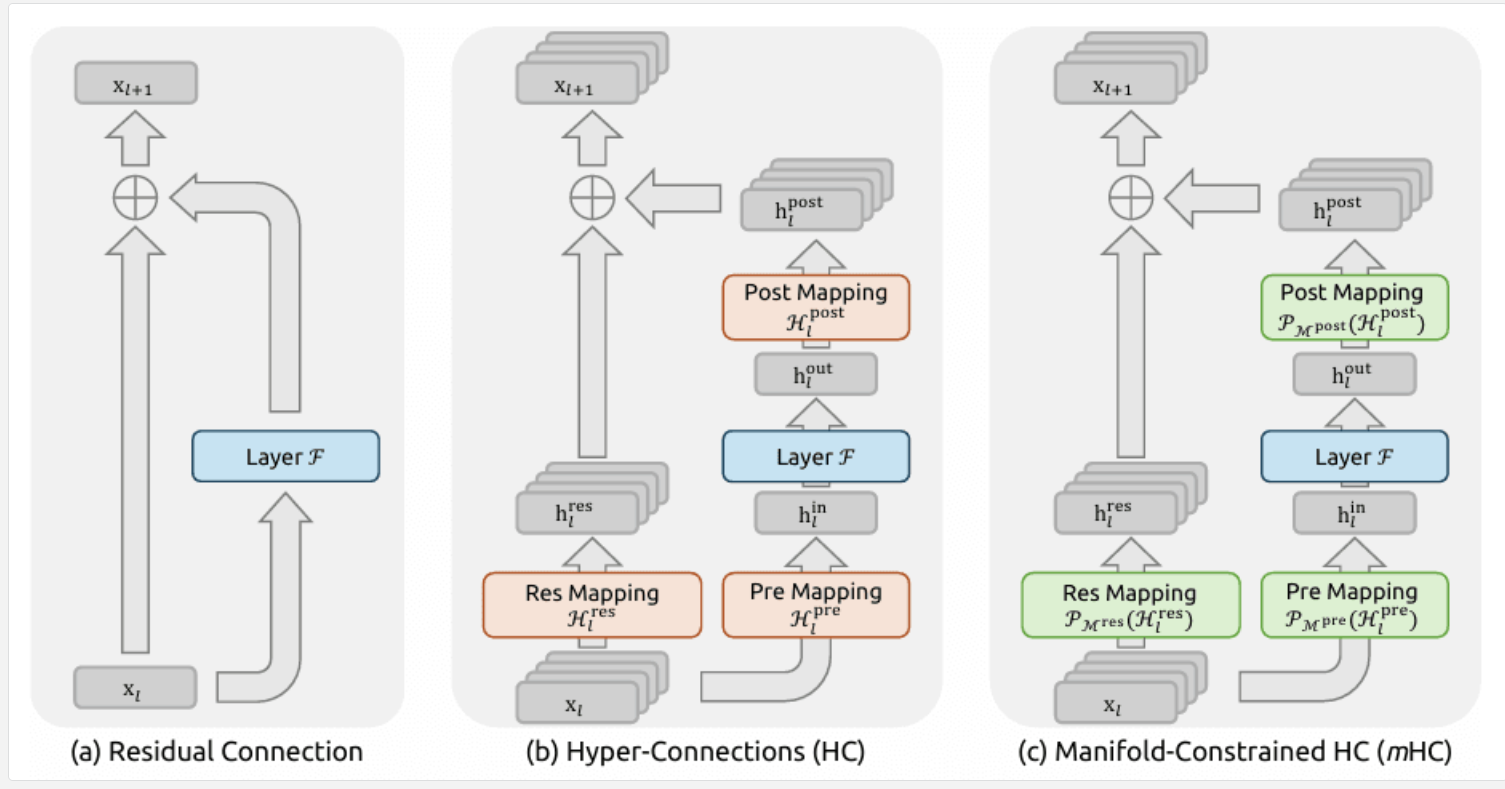
Manifold Constrained Hyperconnections: Preventing Signal Explosions
In a 1.6-trillion-parameter model with dozens of layers, standard architectural setups fail because signals flowing through the network start to amplify, resulting in a mathematical feedback loop called a "signal explosion" that crashes the training run.
DeepSeek solved this by introducing Manifold Constrained Hyperconnections (MHC). They forcefully bound the model's residual connections to a "doubly stochastic matrix" constraint — meaning every row and column must mathematically sum to one. This ensures that the total signal is always conserved and mathematically forbidden from blowing up. To apply this at scale, the team uses the Sinkhorn-Knopp algorithm to run rapid 20-step normalizations at each layer. Through heavily optimized low-level custom GPU programming, they reduced the runtime overhead of this massive calculation to a mere 6.7%, acting as an incredibly cheap insurance policy against catastrophic training crashes.
The Muon Optimizer
The industry-standard optimizer for AI training has long been AdamW, but DeepSeek replaced it with their own custom algorithm called Muon. Muon accelerates learning by using a two-phase process: it first aggressively pushes the system toward convergence with rough adjustments, and then switches to tiny, precise tweaks to carefully stabilize it. This dual approach ensures the model learns faster without losing stability.
Overlapping Computation and Communication
At 1.6 trillion parameters, the model is too large to fit on a single chip or rack, meaning data must constantly be shuttled across data center networks. Every millisecond GPUs spend waiting for data is wasted money.
DeepSeek engineered a deeply choreographed system of "sequential waves." As soon as data for the first wave arrives, GPUs start crunching numbers, while data for the second wave is actively traveling over the network cables in the background. This completely masks network latency. To execute this, they used a specialized language called tilang to write "fused kernels" that merge multiple math operations into a single command, saving massive amounts of memory read/write time. Crucially, they utilized a Z3 SMT solver to mathematically guarantee that their fused kernel code was 100% error-free, preventing silent corruptions.
Curriculum Learning and Anticipatory Routing
To process its staggering 33-trillion-token training dataset, DeepSeek V4 utilizes curriculum learning. It starts with short 4,000-token sequences to learn basic grammar and patterns, gradually stretching its "working memory" to 16K, 64K, and eventually the full 1 million tokens.
To further prevent training crashes (loss spikes) at this massive scale, they introduced anticipatory routing. When the system detects early signs of instability, it dynamically stops looking at real-time noisy parameters and instead references slightly older, historical snapshots of the model. This allows the system to ignore chaotic fluctuations and ride the underlying learning trend, making the model self-stabilizing during training.
DeepSeek V4 is a testament to what constrained resources can inspire. By completely rethinking attention, mathematically preventing instability, choreographing data at a microscopic level, and creatively self-stabilizing the training run, they have birthed an AI that scored a perfect 120/120 on the brutally difficult Putnam 2025 math benchmark. It routinely outperforms or matches closed-source giants — and astonishingly, they have completely open-sourced the model and its underlying architectural secrets for the world.